判断图片中人体站立姿势的机器学习模型

在上篇博文中提到的“获得阿里云开发者挑战赛第四名”的【逸风课程质量检测系统】中,一个有意思的问题是在用#OpenPose识别对图片中的人体25个关键部位(OpenPose的Body_25/pose_iter_584000.caffemodel模型)识别完毕后,如何能判断其具体的“姿势”,比如站姿,坐姿,举手等。下面我就以较为简单的“站姿”为例来介绍如何构建一个机器学习模型来判断照片中的人体姿势。
本文借鉴了一篇机器学习入门简介
和这篇技术性文献
1.数据获取:我在谷歌图片搜索里输入“standing”,从结果中人工下载了100张的图片,类似以下:



然后用OpenPose对图片进行处理,找出图片中所有人物的关键25点:
BODY_PARTS = {"Nose": 0, "Neck": 1, "RShoulder": 2, "RElbow": 3, "RWrist": 4, "LShoulder": 5, "LElbow": 6,
"LWrist": 7, "MidHip": 8, "RHip": 9, "RKnee": 10, "RAnkle": 11, "LHip": 12, "LKnee": 13,
"LAnkle": 14, "REye": 15, "LEye": 16, "REar": 17, "LEar": 18, "LBigToe": 19, "LSmallToe": 20,
"LHeel": 21, "RBigToe": 22, "RSmallToe": 23, "RHeel": 24, "Background": 25}
接下来我做了一个大胆的近似尝试,用3个人体关节节点行程的两条直线的角度来判断是否是站姿:
'right_knee':
pos_list = (BODY_PARTS["RHip"], BODY_PARTS["RKnee"], BODY_PARTS["RAnkle"]) # (9, 10, 11)
'right_ankle':
pos_list = (BODY_PARTS["RShoulder"], BODY_PARTS["RHip"], BODY_PARTS["RAnkle"]) # (2, 9, 11)
'left_knee2':
pos_list = (BODY_PARTS["LShoulder"], BODY_PARTS["LHip"], BODY_PARTS["LKnee"]) # (5, 13, 14)
'left_ankle':
pos_list = (BODY_PARTS["LShoulder"], BODY_PARTS["LHip"], BODY_PARTS["LAnkle"]) # (5, 12, 14)
上图:


把这些数据整理成CSV的格式,即【right_knee, right_ankle, left_knee, left_ankle, 正样本为1/负样本为0】
176.4520214474491,179.03231332332004,179.2842711715813,171.06316406906083,178.80392241312893,175.24413936164845,1
178.75463573323165,170.9097230791777,171.51922965585285,175.53477112926868,177.30219436668375,179.43645312918608,1
150.21441604863574,162.8345559538294,176.8733904668187,174.86212359175016,177.83200460421648,179.73629008164446,1
依照以上描述的步骤,再找一批人体为非站姿(坐姿)的负样本来生成csv:
91.62625719671516,99.51870873627348,146.91836035916165,142.45429881274848,124.44612630173047,144.9642607772789,0
107.17873924499925,60.72755655648946,98.64756474287212,102.35840480271665,65.99220087219447,109.74683660542611,0
152.10439198183784,111.45478724751194,125.05621198613603,143.99714342106506,101.18175421019669,119.87543786023785,0
数据准备工作,也是本人认为机器学习最困难的一步,就算完成啦!
- 对数据集先做出统计学图标,用Pandas可视化Python中的机器学习数据,看看有没有问题。
# box and whisker plots
dataset.plot(kind='box', subplots=True, layout=(3, 3), sharex=False, sharey=False)
pyplot.show()
# histograms
dataset.hist()
pyplot.show()
# scatter plot matrix
scatter_matrix(dataset)
pyplot.show()

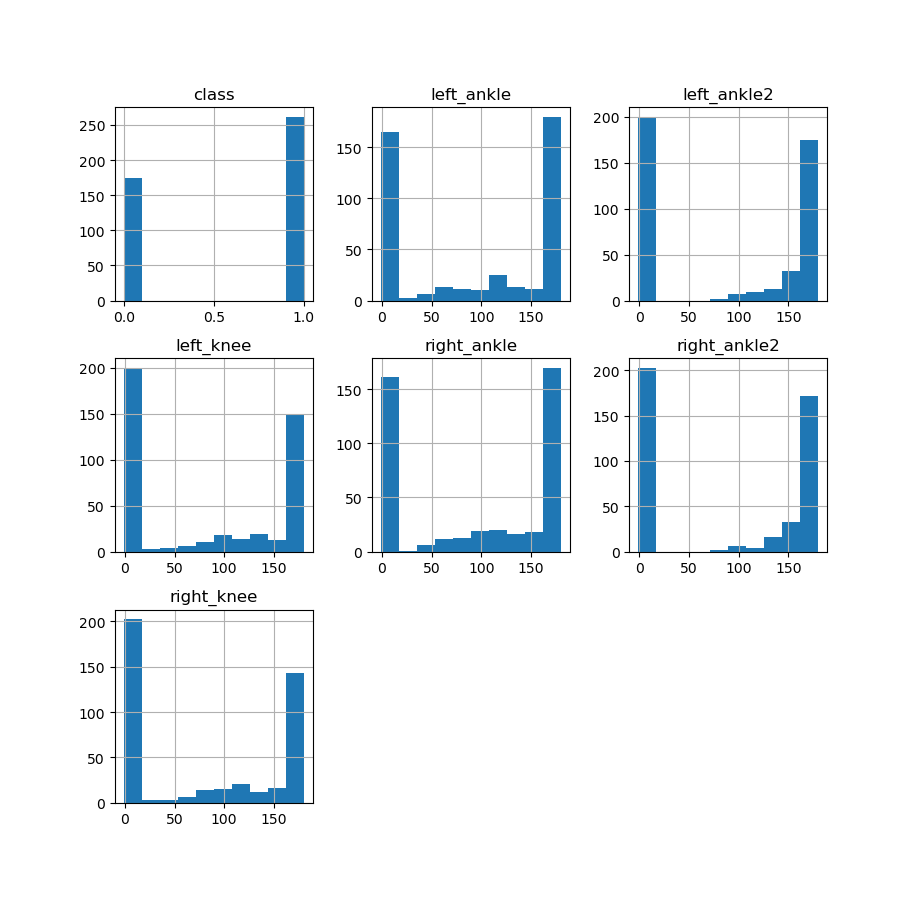

从第三张scatter plot matrix图中可以看到,其实leff_knee和left_ankle的角度程一个线性关系,所以这个两个特征选一即可。
3.分离训练和验证数据集
array = dataset.values
X = array[:, 0:FEATURE_SIZE]
y = array[:, FEATURE_SIZE]
X_train, X_validation, Y_train, Y_validation = train_test_split(X, y, test_size=0.20, random_state=10)
4 针对此问题,粗略评估一下机器学习模型算法的效果更好。
这里用的机器学习算法包括:平均值 (方差)
- 线性回归 0.749580 (0.077388)
- 线性判别分析 0.723866 (0.105559)
- K相邻 0.755546 (0.050928)
- 决策树 0.827311 (0.049214)
- 随机森林 0.827311 (0.047527)
- 高斯朴素贝叶斯 0.672353 (0.113118)
- 支持向量机 0.603445 (0.010712)
models = []
models.append(('LR', LogisticRegression(solver='liblinear', multi_class='ovr')))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('RandomForest', RandomForestClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC(gamma='auto')))
# Spot Check Algorithms
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)
cv_results = cross_val_score(model, X_train, Y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))
LR: 0.749580 (0.077388)
LDA: 0.723866 (0.105559)
KNN: 0.755546 (0.050928)
CART: 0.827311 (0.049214)
RandomForest: 0.827311 (0.047527)
NB: 0.672353 (0.113118)
SVM: 0.603445 (0.010712)
看起来随机森林的准确度是最高的。
5 对所有模型进行训练
# Make predictions on validation dataset
model = SVC(gamma='auto')
model.fit(X_train, Y_train)
# save the model to disk
joblib.dump(model, PREDICTION_MODEL_DIR + MODEL_PREFIX + "_svm.sav")
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, Y_train)
joblib.dump(model, PREDICTION_MODEL_DIR + MODEL_PREFIX + "_knn.sav")
# Make predictions on validation dataset
model = GaussianNB()
model.fit(X_train, Y_train)
# save the model to disk
joblib.dump(model, PREDICTION_MODEL_DIR + MODEL_PREFIX + "_gnb.sav")
# Make predictions on validation dataset
model = DecisionTreeClassifier()
model.fit(X_train, Y_train)
joblib.dump(model, PREDICTION_MODEL_DIR + MODEL_PREFIX + "_decision_tree.sav")
# Make predictions on validation dataset
model = LogisticRegression(solver='liblinear', multi_class='ovr')
model.fit(X_train, Y_train)
joblib.dump(model, PREDICTION_MODEL_DIR + MODEL_PREFIX + "_lr.sav")
# Make predictions on validation dataset
model = RandomForestClassifier()
model.fit(X_train, Y_train)
joblib.dump(model, PREDICTION_MODEL_DIR + MODEL_PREFIX + "_random_forest.sav")
- 结果验证
def load_and_validate_model(prediction_model_name):
# Evaluate predictions
loaded_model = joblib.load(PREDICTION_MODEL_DIR + MODEL_PREFIX + "_" + prediction_model_name + ".sav")
# Evaluate predictions
predictions = loaded_model.predict(X_validation)
print("Accuracy: " + str(accuracy_score(Y_validation, predictions)))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
loaded_model_disp = plot_roc_curve(loaded_model, X_validation, Y_validation)
print("AUC: " + str(loaded_model_disp.roc_auc))
pyplot.show()
load_and_validate_model("random_forest")
load_and_validate_model("svm")
load_and_validate_model("knn")
load_and_validate_model("gnb")
load_and_validate_model("decision_tree")
load_and_validate_model("lr")
结果:
#############random_forest########
Accuracy: 0.8295454545454546
[[23 12]
[ 3 50]]
precision recall f1-score support
0.0 0.88 0.66 0.75 35
1.0 0.81 0.94 0.87 53
accuracy 0.83 88
macro avg 0.85 0.80 0.81 88
weighted avg 0.84 0.83 0.82 88
AUC: 0.8881401617250673
#############svm########
Accuracy: 0.6022727272727273
[[ 0 35]
[ 0 53]]
precision recall f1-score support
0.0 0.00 0.00 0.00 35
1.0 0.60 1.00 0.75 53
accuracy 0.60 88
macro avg 0.30 0.50 0.38 88
weighted avg 0.36 0.60 0.45 88
AUC: 0.7110512129380054
#############knn########
Accuracy: 0.7045454545454546
[[32 3]
[23 30]]
precision recall f1-score support
0.0 0.58 0.91 0.71 35
1.0 0.91 0.57 0.70 53
accuracy 0.70 88
macro avg 0.75 0.74 0.70 88
weighted avg 0.78 0.70 0.70 88
AUC: 0.852021563342318
#############gnb########
Accuracy: 0.6022727272727273
[[20 15]
[20 33]]
precision recall f1-score support
0.0 0.50 0.57 0.53 35
1.0 0.69 0.62 0.65 53
accuracy 0.60 88
macro avg 0.59 0.60 0.59 88
weighted avg 0.61 0.60 0.61 88
AUC: 0.6107816711590296
#############decision_tree########
Accuracy: 0.7840909090909091
[[21 14]
[ 5 48]]
precision recall f1-score support
0.0 0.81 0.60 0.69 35
1.0 0.77 0.91 0.83 53
accuracy 0.78 88
macro avg 0.79 0.75 0.76 88
weighted avg 0.79 0.78 0.78 88
AUC: 0.8180592991913747
#############lr########
Accuracy: 0.6931818181818182
[[29 6]
[21 32]]
precision recall f1-score support
0.0 0.58 0.83 0.68 35
1.0 0.84 0.60 0.70 53
accuracy 0.69 88
macro avg 0.71 0.72 0.69 88
weighted avg 0.74 0.69 0.69 88
AUC: 0.8323450134770889
完结散花 easy peasy I'm lazy!
正文到此结束
- 本文标签: OpenCV Machine Learning Machine Vision
- 版权声明: 本站原创文章,于2020年07月31日由段行健发布,转载请注明出处